

 Abstract
Abstract HTML
HTML Reference
Reference Related
Related PDF
PDF














-
The acceleration of the Universe's expansion [1, 2], observed in the late 1990s, represents a major challenge in modern physics. This discovery led to the hypothesis of an exotic form of energy, known as dark energy, within the framework of general relativity. The ΛCDM model, which incorporates this energy in the form of a cosmological constant and cold dark matter, is currently the reference model in cosmology, as it successfully explains a wide range of observations, from galaxies to large-scale structures of the Universe. However, the recent accumulation of high-precision cosmological data, such as observations of type Ia supernovae, cosmic microwave background, and baryon acoustic oscillations, has revealed tensions and inconsistencies within the ΛCDM model, suggesting the possibility of missing or incomplete features.
One of the most striking examples of these tensions is the discrepancy at high and low redshift in the Hubble constant,
$ H_{0} $ , which measures the current expansion rate of the Universe. Observations of the cosmic microwave background (CMB) suggest a value of$ H_0 $ = 67.40$ \pm 0.50 $ km s−1 Mpc−1 based on the ΛCDM paradigm [3, 4], while the SH0ES team recently published a measurement of$ H_0 = 73.03 $ $ \pm 1.04 $ km s−1Mpc−1 based on the direct distance scale [5]. This tension, reaching almost 5σ, reveals a significant statistical inconsistency and raises questions about the validity of the ΛCDM model. Additionally, there is another tension related to$ \sigma_8 $ , the parameter that measures the amplitude of matter density fluctuations on a scale of 8$ {\rm h}^{-1} $ Mpc, where h is the Hubble constant in units of 100 km s−1 Mpc−1. This tension arises between the values obtained from CMB measurements based on the ΛCDM model and those from galaxy surveys and weak gravitational lensing observations at low redshifts [6, 7]. These tensions and other issues lead physicists to explore the potential physical causes of these phenomena [8].To resolve these challenges, various modifications have been proposed, affecting both early and late cosmology. Among these modifications, we cite models of dynamic dark energy [7, 9−15], the introduction of new relativistic species in the early Universe [16], and theories of modified gravity [17−24].
Among the various theories of modified gravity, three main approaches can be distinguished. The first one consists of extending the Einstein-Hilbert action, the pillar of general relativity, by introducing arbitrary functions of geometric quantities based on curvature, such as
$ f(R) $ gravity [25] and$ f(G) $ gravity [26, 27]. The second approach relies on the teleparallel equivalent of general relativity (TEGR) [28−30] and explores modifications based on torsion, such as$ f(T) $ gravity [31, 32] and$ f(T, T_{G}) $ gravity [33, 34] ($ T_{G} $ represents the teleparallel analogue of the Gauss-Bonnet term). The third approach, known as symmetric teleparallel gravity, uses non-metricity scalar Q and introduces a function$ f(Q) $ in the Lagrangian to develop new extended theories of gravity [18, 35−38].Within the framework of torsion-based gravity theories,
$ f(T) $ gravity provides a novel alternative for explaining the accelerated expansion of the Universe without the need for dark energy [31], as well as an alternative to inflation without requiring an inflaton field [39, 40]. However, a key challenge for any modified gravity theory is selecting a viable function from numerous possible options. The general process involves considering various specific forms within a general class, applying them in a cosmological framework, predicting dynamic behaviors at both the background and perturbation levels, and using observational data to constrain the involved parameters or exclude certain theoretical forms [41]. The literature often studies three viable$ f(T) $ gravity scenarios: power law, exponential square root form, and exponential form [31, 42].In this paper, we proceed differently by using machine learning (ML) to construct
$ f(T) $ gravity. ML has achieved numerous successes in cosmology [43], particularly in distinguishing between standard and modified gravity theories using statistically similar weak lensing maps [44] and in reducing scatter in cluster mass estimates [45]. Among the most promising ML approaches are genetic algorithms (GAs). A GA is a computer simulation that stochastically searches for an optimal solution to a given problem. It evaluates a set of candidate solutions, called "individuals," grouped into a "population." Through an iterative process of crossover and mutation, guided by a "fitness" function, individuals are selected based on how well they solve the problem. For example, parts of two or more functions (individuals) can be combined to form new functions by crossover processes, while mutations make random changes, such as altering coefficients or exponents. This process of evolution allows GAs to find the best solutions to complex problems effectively. Over generations, the population evolves and converges toward an optimal solution.GAs are robust and promising methods that efficiently explore the search space to find optimal solutions. They have been successfully used in various fields, such as particle physics [46, 47], cosmology [48−50], astronomy, and astrophysics [45, 51].
In this paper, we explore a new approach to reconstruct the form of the function
$ f(T) $ within the framework of$ f(T) $ cosmology, using GAs. Previous studies have used Gaussian processes (GPs) to reconstruct$ f(T) $ and$ f(R, T) $ gravity [41, 52−54]. However, GAs offer a distinct advantage over GPs as they do not require any prior assumptions about the underlying physical model [55], while GPs require the choice of a kernel function. In this regard, one study employed a GA to select the appropriate kernel function that provides the best results [56]. GAs efficiently explore the search space to find a solution close to the global optimum rather than a local one. This is the first application of GAs to reconstruct the forms of modified gravities. Our objective is to determine the form of$ f(T) $ gravity in a model-independent manner, relying solely on Hubble data. To achieve this, we use the$ H(z) $ data obtained from distinct methods: the differential age method [57] and radial BAO method [58], including the latest Dark Energy Spectroscopic Instrument (DESI) BAO [59].$ f(T) $ cosmology presents a crucial advantage for this approach because the torsion scalar T is directly related to$ H(z) $ by the relation$ T = -6H^2 $ . Through GA, we reconstruct$ H(z) $ from the observational data. This reconstruction allows us to determine the form of$ f(T) $ without any assumptions.The remainder of this article is structured as follows. In Sec. II, we provide an overview of the theoretical framework for
$ f(T) $ gravity along with its cosmological equations. Sec. III details the methodology behind GAs and their application to derive the Hubble function$ H(z) $ from observational data. Following this, in Sec. IV, we utilize the reconstructed$ H(z) $ to establish the shape of the$ f(T) $ function independently of any model. Sec. V summarizes the key findings and draws conclusions. -
In this section, we briefly introduce
$ f(T) $ gravity and its applications within a cosmological framework. The torsion-based formulations of gravity utilizes tetrad fields$ e^A {}_\mu $ , which serve as dynamic variables. The Greek indices represent spacetime coordinates, and Latin indices denote tangent space. These tetrads form an orthonormal basis for the tangent space at each point on the manifold. The relationship between the metric$ g_{\mu\nu} $ and tetrads is expressed through the equation$ g_{\mu\nu} = \eta_{AB} e^A{}_{\mu} e^B{}_{\nu}, $

(1) where
$ \eta_{AB} $ is the tangent space metric, generally considered the Minkowski metric with the signature$ \eta_{AB} = \text{diag}(1, -1, -1, -1) $ .In teleparallel gravity, the torsionless Levi-Civita connection is replaced by the Weitzenböck connection, defined as
$ W^\lambda{}_{\nu\mu} \equiv e_A{}^\lambda \partial_\mu e^A{}_\nu $ [60]. This connection leads to zero curvature but non-zero torsion. The associated torsion tensor can then be expressed as$ T^\lambda {}_{\mu \nu} \equiv W^\lambda{}_{\nu\mu} - W^\lambda{}_{\mu\nu} = e_{A}{}^\lambda (\partial_\mu e^A{}_\nu - \partial_\nu e^A{}_\mu). $

(2) The Lagrangian for the teleparallel equivalent of general relativity, based on the torsion scalar, T, is formulated through contractions of this torsion tensor as
$ T \equiv \frac{1}{4} T^{\rho\mu\nu} T_{\rho\mu\nu} + \frac{1}{2} T^{\rho\mu\nu} T_{\nu\mu\rho} - T_{\rho\mu}^{\ \ \rho} T^{\nu\mu}_{\ \ \ \nu}. $

(3) Inspired by
$ f(R) $ extension of general relativity, we begin with the teleparallel equivalent of general relativity to develop various gravitational modifications. Specifically, the simplest extension involves generalizing the torsion scalar T in the action as a ($ T + f(T) $ ) gravity formulation. The action for this theory is given by [41]$ S=\frac{1}{16\pi G}\int_{ }^{ }\mathrm{d}^4xe\left[T+f(T)\right]+\int_{ }^{ }\mathrm{d}^4xeL\mathrm{_m}, $

(4) where G is the gravitational constant, e = det
$ (e^A{}_\mu $ )$ = \sqrt{-g} $ represents the determinant of the tetrad field, and$ L_m $ is the matter Lagrangian included to account for the presence of matter.By varying the action in Eq. (4) with respect to the tetrads, we obtain the following field equations [41]:
$ \begin{aligned}[b]& e^{-1}\partial_{\mu}(e e^\rho{}_{A}S_{\rho}{}^{\mu\nu})[1+f_T]+e^\rho{}_{A}S_{\rho}{}^{\mu\nu}\partial_{\mu}(T)f_{TT} \\&-[1+f_T]e_A{}^{\lambda}T^{\rho}{}_{\mu\lambda}S_{\rho}{}^{\nu\mu}+\frac{1}{4}e_A^{\ \ \nu}[T+f(T)] \\ =\;& 4\pi G e^\rho{}_{A}\overset{{\bf{em}}}{T_\rho{}^{\nu}}, \end{aligned} $

(5) where
$ f_T = \partial f /\partial T $ ,$ f_{TT} = \partial^{2} f /\partial T^{2} $ , with$ \overset{{\bf{em}}}{T_\rho{}^{ \nu}} $ denoting the matter1 energy-momentum tensor, and$ S_{\rho}{}^{\mu\nu} $ is the super-potential defined as$ S_\rho{}^{\phantom{\rho}\mu\nu} \equiv \frac{1}{2} \left( K^{\mu\nu}{}_{\ \rho }+ \delta^\mu_\rho T^{\alpha\nu}{}_{\ \alpha} - \delta^\nu_\rho T^{\alpha\mu}{}_{\ \alpha} \right), $

(6) with
$ K^{\mu\nu}{}_{\rho } \equiv -\dfrac{1}{2} \left( T^{\mu\nu}{}_{\ \ \rho } - T^{\nu\mu}{}_{\ \rho} - T_{\rho}^{\ \ \mu\nu} \right) $ as the contorsion tensor.To apply
$ f(T) $ gravity within a cosmological framework, we consider a homogeneous and isotropic flat geometry, described by the tetrad$ e^A{}_\mu = \text{diag}(1, a(t), a(t), a(t)) $ . This particular tetrad setup corresponds to the spatially flat Friedmann-Lemaître-Robertson-Walker (FLRW) metric$ \mathrm{d}s^2=\mathrm{d}t^2-a^2(t)\left[\mathrm{d}r^2+r^2(\mathrm{d}\theta^2+\mathrm{sin}^2\theta\mathrm{d}\phi^2)\right], $

(7) where
$ a(t) $ is a scale factor.Inserting the vierbein
$ e^A {}_\mu $ into the field equations (Eq. (5)), we obtain the Friedmann equations for$ f(T) $ cosmology as$ H^2 = \frac{8\pi G}{3} \rho_m - \frac{f}{6} + \frac{Tf_T}{3}, $

(8) $ \dot{H} = -\frac{4\pi G(\rho_m + P_m)}{1 + f_T + 2Tf_{TT}}, $

(9) where
$ H \equiv \dfrac{\dot{a}}{a} $ represents the Hubble parameter, and a dot above a variable denotes the derivative with respect to cosmic time t. Furthermore,$ \rho_m $ and$ P_m $ denote the energy density and pressure of matter, respectively. The expression of the torsion scalar in the FRW geometry reads$ T = - 6 H^2. $

(10) From the first Friedmann equation (Eq. (8)), it is possible to define an effective dark energy sector of gravitational origin within
$ f(T) $ cosmology. The energy density and pressure of this sector can be respectively defined as follows:$ \rho_{\rm DE} \equiv \frac{3}{8\pi G} \left[ -\frac{f}{6} + \frac{Tf_T}{3} \right], $

(11) $ P_{\rm DE} \equiv \frac{1}{16\pi G} \left[ \frac{f - f_T T + 2T^2 f_{TT}}{1 + f_T + 2Tf_{TT}} \right], $

(12) and the corresponding equation-of-state parameter can then be expressed as
$ w \equiv \frac{P_{\rm DE}}{\rho_{\rm DE}} = -\frac{f/T - f_T + 2Tf_{TT}}{[1 + f_T + 2Tf_{TT}][f/T - 2f_T]}. $

(13) Finally, the system of cosmological equations is closed by the inclusion of the matter conservation equation
$ \dot{\rho}_m + 3H(\rho_m + P_m) = 0. $

(14) Thus, from Eqs. (8) and (9), the conservation of the effective energy is written as
$ \dot{\rho}_{\rm DE} + 3H(\rho_{\rm DE} + P_{\rm DE}) = 0. $

(15) -
In this section, we first present the process of GAs, and then we apply a GA to reconstruct a model from observational data.
-
GAs operate by mimicking the notion of biological evolution through natural selection, where a set of candidate solutions, referred to as “individuals” (in our case, functions), is grouped into a “population” that evolves over time. The performance of each member is evaluated by a “fitness” function, which, in our analysis, is represented by the chi-square statistic,
$ \chi^2 $ , indicating how well each individual corresponds to the data. The individuals with the best fit in each generation are selected using a tournament selection method (see Ref. [61] for more details). Subsequently, two stochastic operations, mutation and crossover, are applied. Crossover involves combining segments of two or more functions (individuals) to create new functions, while mutations introduce random changes, such as modifying coefficients or exponents. This process is then repeated thousands of times to ensure convergence, allowing the population to evolve gradually toward an optimal solution.A GA is an ML technique specialized in unsupervised symbolic regression of data, where it analytically reconstructs a function that describes the data using one or more variables. The algorithm begins with an initial population of candidate solutions, usually generated randomly using a predefined set of functions referred to as the “grammar” (polynomial, exponential, sine, logarithmic, etc.). This initial population represents the first generation of the algorithm, which evolves over multiple generations through stochastic operations such as crossover and mutation. To illustrate these operations, let us consider two example functions:
$ f_0(x) = 1 + 2x + 3x^2 $ and$ g_0(x) = \sin(x) + \exp(x) $ . The mutation operation randomly modifies the terms in these functions. For instance, the functions might transform into$ f_0(x) \rightarrow f_1(x) = 1 + 2x + x^2 $ and$ g_0(x) \rightarrow g_1(x) = \sin(x^2) + \exp(x) $ . In the first case, the coefficient of the third term changes from 3 to 1, while in the second case, the term x is replaced by$ x^2 $ . Meanwhile, the crossover operation combines terms from two functions to create new ones. For example, combining$ 1 + 2x $ from$ f_1(x) $ and$ \sin(x^2) $ from$ g_1(x) $ results in$ f_1(x) \rightarrow f_2(x) = 1 + 2x + \sin(x^2) $ . Similarly, merging the remaining terms produces$ g_1(x) \rightarrow g_2(x) = x^2 + \exp(x) $ . In each generation, the best-fitting functions are selected to proceed to the next generation. Note that the first generation does not affect the final solution; it only affects the rate of convergence of the GA. This process is repeated thousands of times with different random seeds to effectively explore the functional space to ensure convergence toward the optimal function that best fits the data. Convergence is reached when the$ \chi^2 $ value stabilizes, showing no improvement or change over a few hundred generations.The final output of the GA code is a function that is both continuous and differentiable. However, GA does not inherently estimate the errors associated with the reconstructed functions, which is crucial for the statistical interpretation of the data. To address this limitation, it is necessary to employ a path integral method, as described in [49, 62]. This method estimates errors by analytically calculating a path integral over all possible functions that a GA might explore. This approach to error reconstruction has been evaluated and reported in Ref. [62]. It has been shown to yield error estimates that are both smoother and comparable to those obtained through the bootstrap Monte Carlo method.
-
The error estimates of the derived best-fit function are obtained through the implementation of the “path integral” method, initially proposed by the authors of Ref. [62]. The likelihood functional is
$ {\cal{L}} = {\cal{N}} \exp \left(-\chi^2(f) / 2\right), $

(16) where
$ f(x) $ represents the function reconstructed by the GA, and$ \chi^2(f) $ denotes the associated chi-squared for N data points$ (x_i, y_i, \sigma_i) $ , defined as$ \chi^2(f) \equiv \sum\limits_{i = 1}^N\left(\frac{y_i-f\left(x_i\right)}{\sigma_i}\right)^2. $

(17) Determining the normalization constant
$ {\cal{N}} $ is considerably more complex than in the case of a normal distribution, as it requires integration over all possible functions$ f(x) $ , or in other words, performing a “path integral”$ \int {\cal{D}} f {\cal{N}} \exp \left(-\chi^2(f) / 2\right) = 1. $

(18) Here,
$ {\cal{D}}f $ denotes integration over all possible values of$ f(x) $ . This comprehensive integration is necessary because, during the operation of the GA, a wide variety of candidate functions are explored owing to the stochastic nature of the mutation and crossover operators. Although many of these candidate functions may not provide optimal fits and are eventually discarded, they still contribute to the overall likelihood. Consequently, their influence must be accounted for when calculating the error estimates of the best-fit.The infinitesimal measure,
$ {\cal{D}}f $ , can be expressed as$ {\cal{D}}f=\prod_{i=1}^N{\rm d}f_i $ , where$ \mathrm{d}f_i $ and$ f_i $ denote$ {\rm d}f(x_i) $ and$ f(x_i) $ , respectively. For the time being, we assume that the function values$ f(x_i) $ and$ f(x_j) $ at distinct points$ x_i $ and$ x_j $ are independent. Therefore, Eq. (18) can be reformulated as$ \begin{aligned}[b]\int {\cal{D}}f{\cal{L}}=\;&\int_{-\infty}^{+\infty}\prod_{i=1}^N{\rm d}f_i{\cal{N}}\exp\left(-\frac{1}{2}\sum_{i=1}^N\left(\frac{y_i-f_i}{\sigma_i}\right)^2\right) \\ =\;&\prod_{i=1}^N\int_{-\infty}^{+\infty}\mathrm{ }\mathrm{d}f_i{\cal{N}}\exp\left(-\frac{1}{2}\left(\frac{y_i-f_i}{\sigma_i}\right)^2\right) \\=\;&{\cal{N}}\cdot(2\mathit{\pi})^{N/2}\prod_{i=1}^N \sigma_i \\ =\;&1,\end{aligned} $

(19) which leads to
$ {\cal{N}} = \left[(2\pi)^{N/2} \prod_{i = 1}^{N} \sigma_i\right]^{-1} $ . Consequently, the likelihood becomes$ {\cal{L}} = \frac{1}{(2 \pi)^{N / 2} \prod_{i = 1}^N \sigma_i} \exp \left(-\chi^2(f) / 2\right). $

(20) Considering our assumption that the function f evaluated at each point
$ x_i $ is independent,$ {\cal{L}}_i \equiv \frac{1}{(2 \pi)^{1 / 2} \sigma_i} \exp \left(-\frac{1}{2}\left(\frac{y_i-f_i}{\sigma_i}\right)^2\right). $

(21) Now, we can calculate the 1σ error,
$ \delta f_i $ , around the best-fit function$ f_{\text{bf}}(x) $ at a point$ x_i $ as$ \begin{aligned}[b]CI\left(x_i,\delta f_i\right)=\; & \int_{f_{\mathrm{bf}}\left(x_i\right)-\delta f_i}^{f\mathrm{_{bf}}\left(x_i\right)+\delta f_i}\mathrm{d}f_i\frac{1}{(2\pi)^{1/2}\sigma_i}\exp\left(-\frac{1}{2}\left(\frac{y_i-f_i}{\sigma_i}\right)^2\right) \\ =\; & \frac{1}{2}\Bigg(\text{erf}\left(\frac{\delta\mathrm{f}_{\mathrm{i}}+\mathrm{f}_{\mathrm{bf}}\left(\mathrm{x}_{\mathrm{i}}\right)-\mathrm{y}_{\mathrm{i}}}{\sqrt{2}\sigma_{\mathrm{i}}}\right) \\ & +\text{erf}\left(\frac{\delta\mathrm{f}_{\mathrm{i}}-\mathrm{f}_{\mathrm{bf}}\left(\mathrm{x}_{\mathrm{i}}\right)+\mathrm{y}_{\mathrm{i}}}{\sqrt{2}\sigma_{\mathrm{i}}}\right)\Bigg).\end{aligned} $

(22) To determine the errors
$ \delta f_i $ corresponding to the$ 1\sigma $ error of a normal distribution, we numerically solve the following equation:$ C I\left(x_i, \delta f_i\right) = \text{erf}(1 / \sqrt{2}). $

(23) While it is possible to compute the
$ 1\sigma $ error,$ \delta f_i $ , of the best-fit function$ f_{\mathrm{bf}}(x) $ at each point$ x_i $ , this approach yields discrete error estimates at individual data points. Such pointwise estimates do not align with our objective of obtaining a smooth, continuous, and differentiable error function. For that, it is necessary to create a new chi-squared defined as$ \chi_{C I}^2\left(\delta f_i\right) = \sum\limits_{i = 1}^N\left(C I\left(x_i, \delta f_i\right)-\text{erf}(1 / \sqrt{2})\right)^2. $

(24) We also parameterize
$ \delta f $ using a second-order polynomial form,$ \delta f(x) = a + bx + cx^2 $ . The coefficients$ (a, b, c) $ are determined by minimizing the combined chi-squared function,$ \chi^2(f_{\mathrm{bf}} + \delta f) + \chi^2_{CI}(\delta f) $ , where$ \chi^2 $ is defined in Eq. (17) and$ \chi^2_{CI} $ in Eq. (24). This approach ensures that the$ 1\sigma $ confidence region for the best-fit function$ f_{\mathrm{bf}}(x) $ lies within the interval$ [f_{\mathrm{bf}}(x) - \delta f(x),\ f_{\mathrm{bf}}(x) + \delta f(x)] $ . We perform a simultaneous fit of both chi-squares to ensure that the resulting error region reflects only minor variations around the best-fit solution, rather than the entire infinite-dimensional functional space explored by the GA.The approach described above applies to uncorrelated data. In cases where data points are correlated, it is necessary to incorporate the chi-squared term accounting for these correlations. For more details on the path integral approach to the error estimation in the context of correlated data, we refer the reader to Ref. [62]. For instance, if the best-fit function derived by the GA is the Hubble parameter,
$ H(z) $ , this procedure can be adapted to determine the corresponding errors. Subsequently, the errors associated with each quantity related to$ H(z) $ can be derived using error propagation techniques [55]. For example, in the case of the deceleration parameter, we have$ q_{\mathrm{GA}}(z)=-1+(1+z)\frac{\mathrm{d}\ln H_{\mathrm{GA}}}{\mathrm{d}z}, $

(25) which implies that the error is
$ \begin{aligned}[b]\delta q(z)=\; & (1+z)\delta\left[\frac{\mathrm{d}\ln H}{\mathrm{d}z}\right]=(1+z)\frac{\mathrm{d}}{\mathrm{d}z}[\delta\ln H] \\ =\; & (1+z)\frac{\mathrm{d}}{\mathrm{d}z}\left[\frac{\delta H}{H_{\mathrm{GA}}}\right].\end{aligned} $

(26) -
In our analysis, we utilize Hubble measurements obtained through two primary approaches. The first approach involves the clustering of galaxies or quasars, enabling a direct measurement of the Hubble expansion by identifying the Baryon Acoustic Oscillation (BAO) peak in the radial direction [58]. The second approach relies on the differential age technique, commonly referred to as the cosmic chronometers (CC) method. This method is based on the relationship between the Hubble parameter and time derivative of the redshift of distant objects, such as massive elliptical galaxies. This relationship is expressed as
$ H(z)=-\dfrac{1}{(1+z)}\dfrac{{\rm d}z}{{\rm d}t} $ [57], which enables the estimation of$ H(z) $ by measuring the relative ages of these objects at different redshifts.In our work, we use 64
$ H(z) $ data points of the Hubble parameter, which include 32 points from CC measurements and 32 points from BAO data, as presented in [63]. The BAO dataset consists of 27 points from previous BAO data combining independent datasets, such as WiggleZ [64], BOSS DR12 [65], and eBOSS DR16 [66−71], along with five points from the most recent Dark Energy Spectroscopic Instrument (DESI) BAO results [59]. Within the CC dataset, 15 data points were provided by Moresco et al. [72−74], all obtained using the same method. For more details on the correlation between these points, we refer the reader to Ref. [75]. In our reconstruction, we take into account the covariance between these points, as detailed in their open-source program2 . These data are summarized in Table 1.CC data z $ H(z) $ 

$ \sigma_{H} $ 

Ref. z $ H(z) $ 

$ \sigma_{H} $ 

Ref. 0.07 69.0 19.6 [76] 0.4783 83.8 10.2 [73] 0.09 69.0 12.0 [77] 0.48 97.0 62.0 [80] 0.12 68.6 26.2 [76] 0.5929 107.0 15.5 [72] 0.17 83.0 8.0 [78] 0.6797 95.0 10.5 [72] 0.1791 78.0 6.2 [72] 0.75 98.8 33.6 [81] 0.1993 78.0 6.9 [72] 0.7812 96.5 12.5 [72] 0.2 72.9 29.6 [76] 0.8754 124.5 17.4 [72] 0.27 77.0 14.0 [78] 0.88 90.0 40.0 [80] 0.28 88.8 36.6 [76] 0.90 117.0 23.0 [78] 0.3519 85.5 15.7 [72] 1.037 133.5 17.6 [72] 0.3802 86.2 14.6 [73] 1.30 168.0 17.0 [78] 0.4 95.0 17.0 [78] 1.363 160.0 33.8 [74] 0.4004 79.9 11.4 [73] 1.43 177.0 18.0 [78] 0.4247 90.4 12.8 [73] 1.53 140.0 14.0 [78] 0.4497 96.3 14.4 [73] 1.75 202.0 40.0 [78] 0.47 89.0 49.6 [79] 1.965 186.5 50.6 [74] BAO data z $ H(z) $ 

$ \sigma_{H} $ 

Ref. z $ H(z) $ 

$ \sigma_{H} $ 

Ref. 0.24 79.69 2.99 [58] 0.57 96.80 3.40 [86] 0.30 81.70 6.22 [82] 0.59 98.48 3.19 [83] 0.31 78.17 6.74 [83] 0.6 87.90 6.10 [64] 0.34 83.17 6.74 [58] 0.61 97.30 2.10 [65] 0.35 88.1 9.45 [84] 0.64 98.82 2.99 [83] 0.36 79.93 3.93 [83] 0.978 113.72 14.63 [87] 0.38 81.50 1.90 [65] 1.23 131.44 12.42 [87] 0.40 82.04 2.03 [83] 1.48 153.81 6.39 [66] 0.43 86.45 3.68 [58] 1.526 148.11 12.71 [87] 0.44 82.60 7.80 [64] 1.944 172.63 14.79 [87] 0.44 84.81 1.83 [83] 2.3 224 8 [88] 0.48 87.79 2.03 [83] 2.36 226.0 8 [89] 0.56 93.33 2.32 [83] 2.4 227.8 5.61 [90] 0.57 87.60 7.80 [85] DESI data z $ H(z) $ 

$ \sigma_{H} $ 

Ref. z $ H(z) $ 

$ \sigma_{H} $ 

Ref. 0.51 97.21 2.83 [59] 1.32 147.58 4.49 [59] 0.71 101.57 3.04 [59] 2.33 239.38 4.80 [59] 0.93 114.07 2.24 [59] Table 1.
$ H(z) $ dataset and corresponding uncertainties,$ \sigma_H $ , employed in our analysis (expressed in km s−1 Mpc−1).To reconstruct the history of cosmic dynamics evolution from the
$ H(z) $ data, we perform a model-independent reconstruction of the Hubble parameter using a GA. For the likelihood$ \chi^2 $ of the$ H(z) $ data, we use the following expressions, depending on whether the datasets are correlated or uncorrelated.For correlated datasets, the chi-squared is given by
$ \chi^2_{\rm Corr} = \bigg( H_i - H_{\text{GA}}(z_i) \bigg)^T C_{ij}^{-1} \bigg( H_j - H_{\text{GA}}(z_j) \bigg), $

(27) while for uncorrelated datasets, it is written as
$ \chi_{\mathrm{UnCorr}}^2=\sum\limits_{i=1}^N\left(\frac{H_i-H_{\text{GA}}(z_i)}{\sigma_{H,i}}\right)^2, $

(28) where
$ H_i $ and$ \sigma_{H,i} $ represent the observed values of the Hubble parameter and their associated uncertainties at each redshift$ z_i $ , respectively.$ H_{\text{GA}}(z) $ corresponds to the theoretical prediction of the Hubble parameter derived using the GA, while$ C_{ij}^{-1} $ is the inverse covariance matrix of the correlated data. Finally, N denotes the number of data points considered.The total
$ \chi^2 $ is then given by$ \chi_H^2=\chi_{\mathrm{Corr}}^2+\chi_{\mathrm{UnCorr}}^2. $

(29) It is important to note that when deriving a model from a dataset using GAs, we do not make any prior assumptions, such as a specific dark energy model or flat Universe. This ensures that the obtained results do not depend on a particular choice. Furthermore, owing to the very nature of how GAs operate, one can ensure that the final solution does not prematurely converge to a local optimum but rather approaches the global one. For the dataset in Table 1, the best solution
$ H_{GA}(z) $ , derived from the GA and which minimizes$ \chi_H^2 $ , is obtained as follows$ H_{GA}(z) = H_{0} \Big(1 + z\big(0.682 + 0.222z - 0.036z^2\big)^2\Big), $

(30) where
$ H_{0} = (68.56 \pm 8.59) $ km/s/Mpc. The best-fit$ \chi^2 $ value for the GA model is 41.43, compared to 42.47 for the ΛCDM best-fit model, with the best-fit values$ \Omega_{m0} = 0.279 \pm 0.014 $ and$ H_0 = 69.45 \pm 1.03 $ km/s/Mpc obtained through an MCMC analysis. The GA model accurately fits the observed data, achieving a minimal value of$ \chi^2 $ comparable to that of the ΛCDM best-fit model. Fig. 1 shows the reconstructed Hubble parameter compared to the ΛCDM model.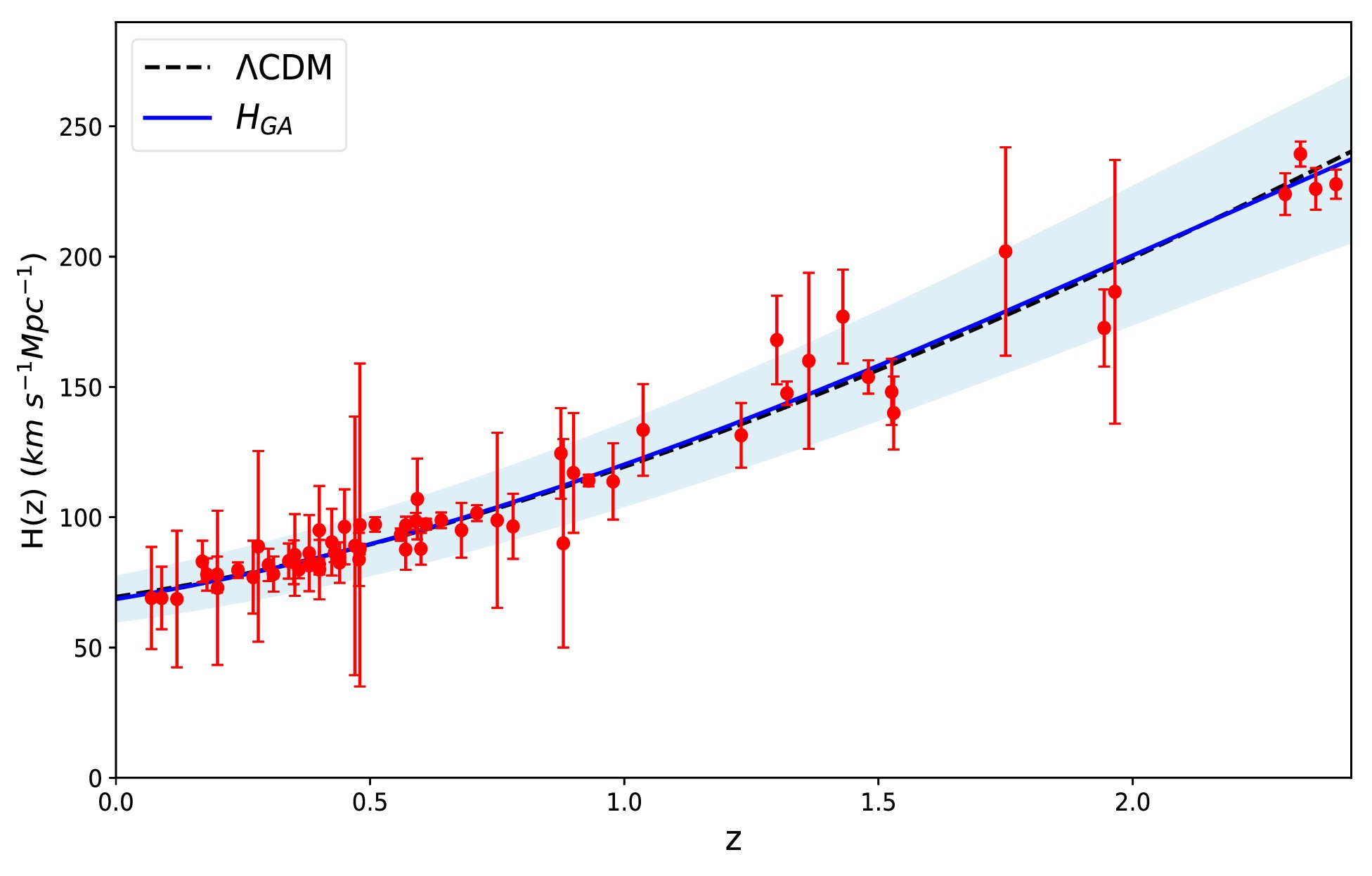
Figure 1. (color online)
$ H(z) $ data compilation, along with the ΛCDM best-fit (dashed black curve) and GA best-fit (solid blue curve). The blue region represents the$ 1\sigma $ confidence level for the GA model, while the actual data points are depicted as red points.Other non-parametric techniques commonly used for model-independent reconstructions of cosmological functions include GPs, Smoothing Methods (SMs), and Artificial Neural Networks (ANNs). In Ref. [91], the authors applied GP, SM, and GA to reconstruct the Hubble parameter and luminosity distance, finding that the three methods yielded similar results. Among these techniques, GP and ANN are the most widely used in cosmology. However, GP reconstructions require the choice of both a kernel function and a fiducial model for the mean function, as previously mentioned. The choice of the kernel can sometimes influence the reconstruction outcome [92]. Similarly, for ANN, the selection of hyperparameters, such as activation functions and the number of layers, can affect the reconstruction quality, and generally, a larger amount of training data is needed to ensure reliable results. An advantage of GA-based approaches is their independence from any predefined assumptions on the form of the reconstructed functions. Furthermore, GAs naturally provide analytical functions that describe the provided data.
-
In the preceding subsection, we used a GA on the
$ H(z) $ data to achieve a model-independent reconstruction of$ H(z) $ . Thus, we can now use this reconstructed form of$ H(z) $ to derive the function$ f(T) $ itself.Our analysis is based on the relationship between the torsion scalar, T, of the
$ f(T) $ gravity and the Hubble parameter, H, as described by Eq. (10), specifically,$ T = -6H^2 $ , which is a simple function of H. Because the dynamics of$ f(T) $ are governed by the Friedmann equation (Eq. (8)) we can express them as a function of the redshift z. Consequently,$ f_T $ can be expressed as follows:$ f_T\equiv\frac{\mathrm{d}f(T)}{\mathrm{d}T}=\frac{\mathrm{d}f/\mathrm{d}z}{\mathrm{d}T/\mathrm{d}z}=\frac{f'}{T'}, $

(31) where the prime denotes the derivative with respect to z. By substituting Eq. (31) into Eq. (8), we can rewrite the latter as
$ f'(z) = 6 \frac{H'(z)}{H(z)} \left[ H^2(z) - \frac{8 \pi G}{3} \rho_m(z) + \frac{f(z)}{6} \right]. $

(32) Finally, by incorporating the EoS parameter for the matter sector, we arrive at the final equation
$ f'(z) = 6 \frac{H'(z)}{H(z)} \left[ H^2(z) - H_0^2 \Omega_{m0}(1+z)^3 + \frac{f(z)}{6} \right]. $

(33) By using the Hubble parameter derived from GA and its derivative, we solve the provided expression numerically. However, to solve this equation, initial conditions must be imposed. By evaluating the Friedmann equation at
$ z = 0 $ , where the ΛCDM model is assumed to dominate, i.e.,$ f_{T}(z = 0) \approx 0 $ , we obtain$ f(z = 0) = -6 H_{0}^{2} (1 - \Omega_{m0}). $

(34) Finally, by utilizing Eq. (33) and the relationship between T and H, as well as the reconstruction of
$ H(z) $ , we reconstruct the form of$ f(T) $ gravity in a model-independent manner. In the left panel of Fig. 2, we present the mean curve for the reconstructed$ f(T) $ resulting from our analysis, which constitutes the main result of this study, along with the standard ΛCDM model represented by a dashed red line. The ΛCDM model corresponds to a constant value, specifically$ f(T) = -2\Lambda = -6H_0^2 (1-\Omega_{m0}) $ . Furthermore, additional information about the functional form of the reconstructed$ f(T) $ gravity can be obtained. By applying the curve fitting method, we find that the reconstructed$ f(T) $ curve can be well-approximated by a second-degree polynomial function as follows: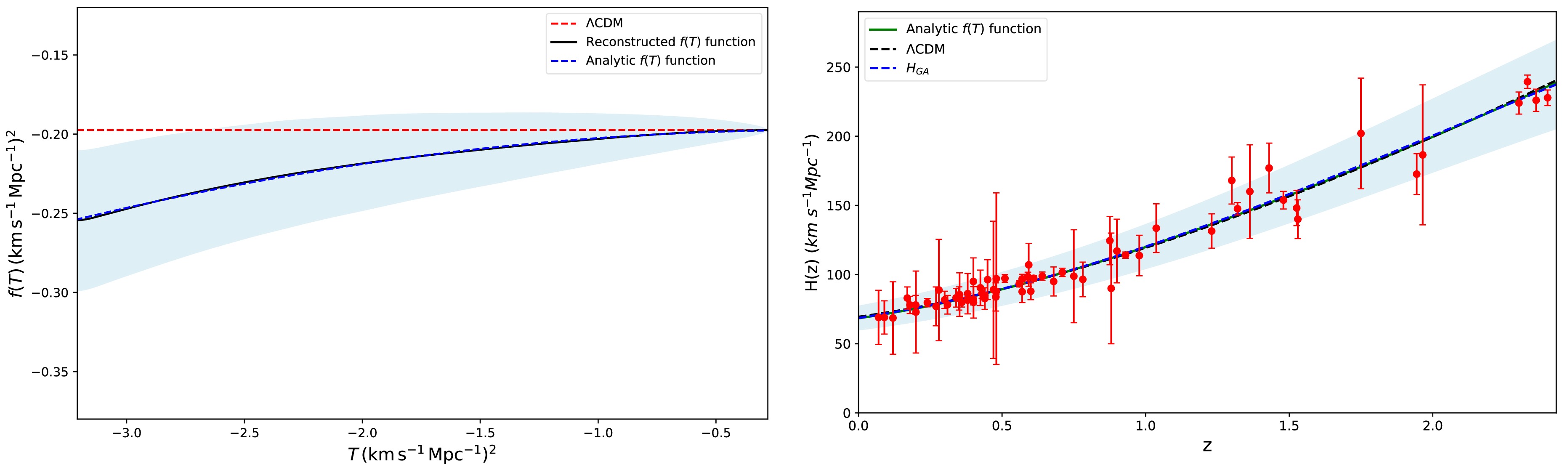
Figure 2. (color online) Left: Independent reconstruction of the
$ f(T) $ function from$ H(z) $ data using GA imposing$ \Omega_{m0} = 0.3 $ . The black curve shows the mean reconstructed curve, the blue area indicates the$ 1\sigma $ confidence level, the dashed blue curve represents the best-fit analytical model, and the dashed red line corresponds to the ΛCDM model. Both T and$ f(T) $ are divided by$ 10^5 $ . Right: Evolution of$ H(z) $ from GA (dashed blue curve and blue region), the reconstructed$ f(T) $ model (green curve), and the ΛCDM model (dashed black curve).$ f(T) = \alpha T_0 + \beta T + \gamma T_0 \left(\frac{T}{T_0}\right)^2, $

(35) with the dimensionless parameters
$ \alpha = 0.69825 $ ,$ \beta = -0.00031 $ , and$ \gamma = 0.00153 $ and$ T_0 $ denoting the value of T at the current time, the above analytic function efficiently describes the model-independent reconstructed$ f(T) $ form (with an accuracy of$ R^{2} \approx 0.9999 $ ). This result is also illustrated in the left panel of Fig. 2. Moreover, the cosmological constant lies within the$ 1\sigma $ region of the reconstructed$ f(T) $ model over a significant time range.In the present work, we proposed the parametrization of Eq. (35) for the function
$ f(T) $ , motivated by its ability to accurately reproduce the behavior of the reconstructed function derived from Hubble data through GA analysis. The effectiveness of a quadratic form was anticipated because at late times, when$ H \approx H_0 $ and thus$ T \approx T_0 $ , a Taylor expansion around$ T_0 $ can be performed, with the quadratic term naturally emerging as the first significant correction beyond the constant and linear terms. This parametrization is further supported by previous studies, where quadratic forms of$ f(T) $ have been shown to effectively describe cosmological dynamics at late times [41, 93−96].As a complementary test of our analysis, we compare the evolution of
$ H(z) $ derived from the reconstructed$ f(T) $ model with that of the ΛCDM model. For this purpose, we substitute the reconstructed$ f(T) $ model into the Friedmann equation (Eq. (8)) and extract the solution for$ H(z) $ . The right panel of Fig. 2 displays the$ H(z) $ curves obtained from the GA, reconstructed$ f(T) $ model, and ΛCDM model. The results demonstrate strong agreement among the three models. This comparison provides additional validation of our results, further reinforcing the effectiveness of the reconstructed$ f(T) $ model in describing the observed data.To provide further insight into the reconstructed dynamics, we plot the evolution of the effective dark energy density parameter
$ \Omega_{\rm DE} = \frac{8\pi G \rho_{\rm DE}}{3 H^2} $ and deceleration parameter$ q(z) $ , obtained independently using the reconstruction results of$ H(z) $ and$ f(T) $ . These reconstructions are presented in Fig. 3. In the left panel of Fig. 3, we plot the evolution of$ \Omega_{\rm DE} $ as a function of redshift. It is observed that the effective dark energy is currently dominant, with a density parameter of approximately 0.693, which is consistent with current observations. The right panel of Fig. 3 illustrates the evolution of the deceleration parameter$ q(z) $ for three cases: the ΛCDM model, GA, and analytical function$ f(T) $ (Eq. 34). The parameter$ q(z) $ is crucial for determining whether the Universe is accelerating and is defined by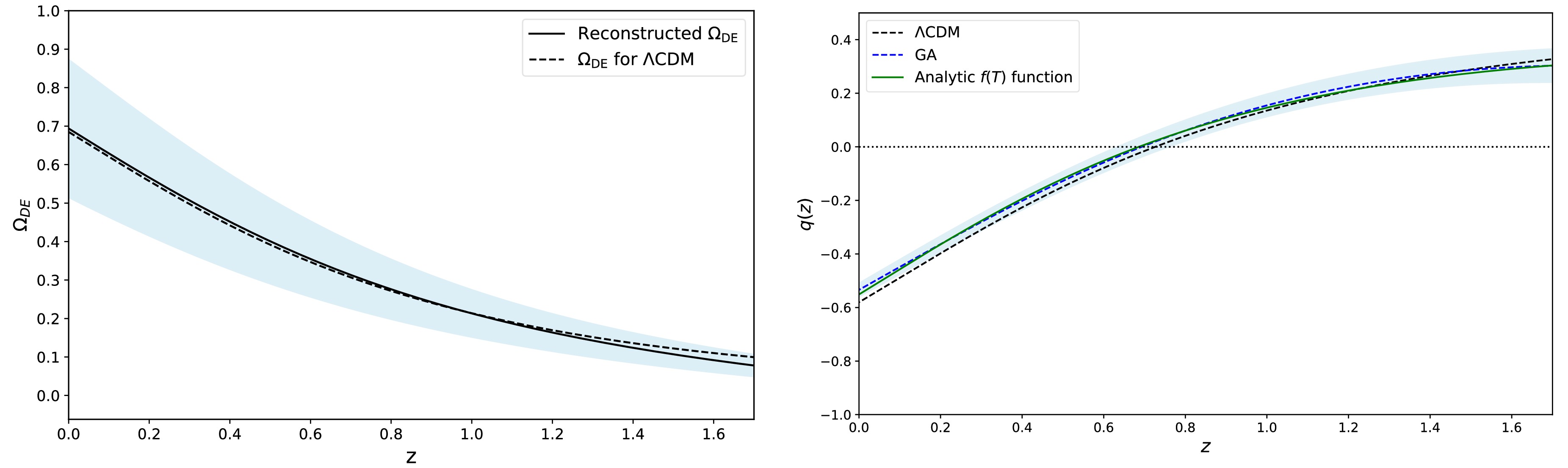
Figure 3. (color online) Left:Reconstructed form of the effective dark energy density parameter
$ \Omega_{\rm DE} $ , where the solid black line represents the reconstructed$ f(T) $ model, and the blue region corresponds to the$ 1\sigma $ error. Right: Deceleration parameter$ q(z) $ , where the green line corresponds to the$ f(T) $ model, and the dashed blue line with the blue region show the GA reconstruction and$ 1\sigma $ error, respectively. In both panels, the dashed black line represents the ΛCDM model.$ q(z)=-\frac{\ddot{a}a}{\dot{a}^2}\ =-1+(1+z)\frac{\mathrm{d}\ln H(z)}{\mathrm{d}z}, $

(36) where a represents the scale factor, and the dots indicate derivatives with respect to cosmic time. In the last two scenarios, the deceleration parameter
$ q(z) $ shifts from positive (indicating deceleration) to negative (indicating acceleration) at low redshifts, similar to what is observed in the ΛCDM model. This behavior indicates a transition from a decelerating to accelerating Universe. In both panels of Fig. 3, the blue regions correspond to the 1σ confidence level.To conclude this subsection, we quantify the impact of DESI data on the reconstruction process by performing a complementary analysis that excludes DESI measurements. The Hubble parameter,
$ H(z) $ , reconstructed from GA, is presented in the left panel of Fig. 4, yielding$ H_0 = 64.62 \pm 9.98 \, \text{km/s/Mpc} $ . This relatively low value, accompanied by a large uncertainty, is primarily driven by the previous BAO measurements, which are known to favor lower values of$ H_0 $ [63]. By contrast, incorporating DESI data, particularly its high-precision measurements at intermediate and high redshifts, yields a more precise reconstruction, with$ H_0 = 68.56 \pm 8.59 \, \text{km/s/Mpc} $ , as discussed in Subsection 3.3. This result aligns more closely with local determinations and demonstrates a 13.9% reduction in uncertainty, highlighting the enhanced constraining power provided by DESI. A comparable behavior is observed in the reconstruction of the$ f(T) $ function. As shown in the right panel of Fig. 4, excluding DESI data leads to larger deviations from the ΛCDM model and broader confidence intervals, especially at high redshifts, where observational constraints are otherwise limited. By contrast, the reconstruction obtained with DESI data, as shown in the left panel of Fig. 2, remains well within the$ 1\sigma $ region around ΛCDM model across a wide redshift range, indicating improved stability and accuracy. These findings demonstrate the crucial role of DESI in enhancing the robustness, precision, and fidelity of the reconstruction.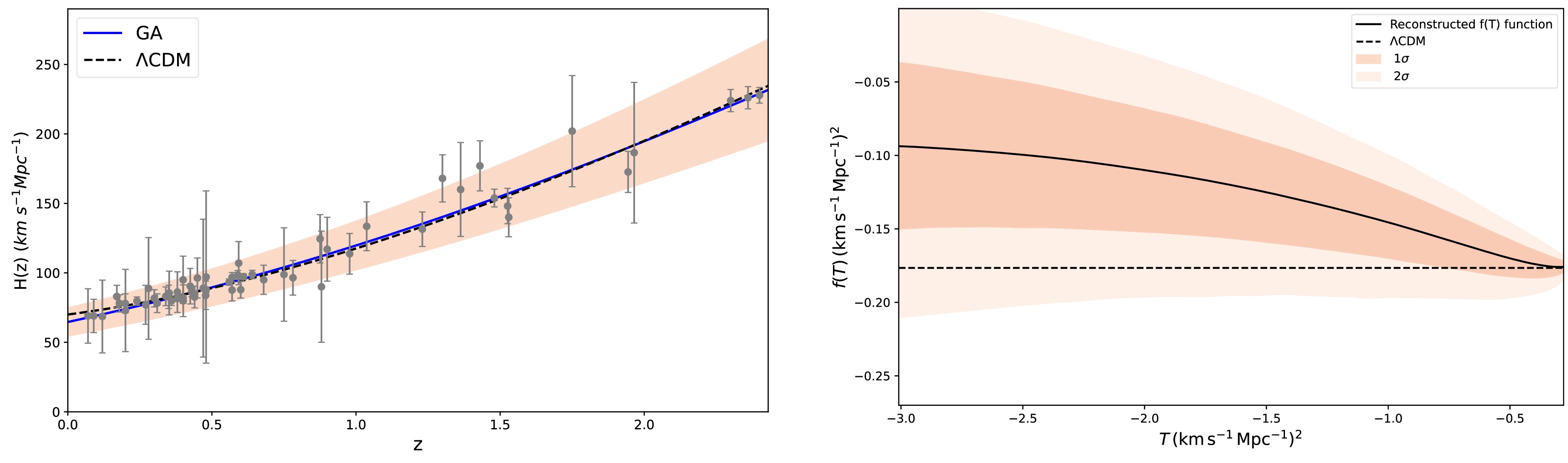
Figure 4. (color online) Left: Compilation of
$H(z)$ data excluding DESI measurements, along with the GA best-fit model (blue line). The red region indicates the$1\sigma$ confidence level for the GA model, while the actual data points are depicted as gray points. Right: Independent reconstruction of the$f(T)$ function. The black curve shows the reconstructed function, with light and dark red regions representing the$1\sigma$ and$2\sigma$ confidence levels, respectively. Both T and$f(T)$ are divided by$10^5$ . In both panels, the dashed black line represents the ΛCDM model. -
In this work, we used data from the Hubble parameter
$ H(z) $ and a GA to reconstruct the function$ f(T) $ in a model-independent manner. GA analysis was applied to Hubble measurements, including Cosmic Chronometers, Baryon Acoustic Oscillations, and the latest cosmological data released by the DESI collaboration, which allowed us to reconstruct$ H(z) $ without relying on a specific model, as presented in Sec. III. We derived a Hubble parameter function that more accurately describes the observational data. Moreover,$ f(T) $ gravity theory has the advantage that the torsion scalar is a simple function of$ H(z) $ , namely$ T = -6H^2 $ . Therefore, knowing$ H(z) $ and the value of the Hubble constant derived by GA,$ H_0 = (68.56 \pm 8.59) $ km/s/Mpc, we reconstructed$ f(T) $ , which is a key result of this work.The left panel of Fig. 2 illustrates the reconstructed function
$ f(T) $ as a function of the torsion scalar, T, where the black curve represents the mean reconstructed function, and the blue region indicates the$ 1\sigma $ confidence level. The red dashed line represents the ΛCDM model, which is a constant, i.e.,$ f_{\Lambda\text{CDM}}(T) = -2\Lambda = -6 H_{0}^{2}(1-\Omega_{m0}) $ . Additionally, the functional form of the reconstructed$ f(T) $ gravity provides further insight. Using a curve fitting method, we find that the reconstructed$ f(T) $ curve is well-approximated by a second-degree polynomial function.Afterwards, we used the reconstructed
$ f(T) $ model to compare the evolution of the parameter$ H(z) $ with that of the ΛCDM using the Friedmann equation. The right panel of Fig. 2 presents the$ H(z) $ curves obtained from the GA, reconstructed$ f(T) $ model, and ΛCDM model. We observe significant agreement among the three models. This comparison serves as additional cross-validation of our results, further reinforcing the effectiveness of the$ f(T) $ model in describing the observational data. We also used the reconstructed$ f(T) $ model to plot the effective dark energy density parameter and deceleration parameter. We observed that these quantities align with the predictions of the ΛCDM model. The reconstruction of these quantities as a function of redshift z, along with the$ 1\sigma $ confidence level, is presented in Fig. 3.Furthermore, to assess the impact of the DESI data on the reconstruction, we performed a complementary analysis excluding these measurements. We found that the inclusion of DESI data significantly improves the precision and robustness of the reconstruction.
In summary, we followed a reconstruction procedure that is completely model-independent, based solely on Hubble data, including Cosmic Chronometers, Baryon Acoustic Oscillations, and the latest cosmological data released by the DESI collaboration. This paper presents the first implementation of a GA to reconstruct the form of
$ f(T) $ gravity. Moreover, our method offers several advantages over traditional or non-parametric models, such as cosmography, which faces convergence issues at high redshifts, or GPs, which require the choice of a kernel function and reference model [97]. Our approach requires neither a kernel function nor a reference model and remains entirely model-independent. We demonstrated the effectiveness of GA in reconstructing the function$ f(T) $ in a model-independent manner. The reconstructed$ f(T) $ model is in excellent agreement with the observed data. In our future work, we will focus on extending our GA analysis to include additional datasets, such as supernovae and large-scale structure data. This will allow us to obtain more precise results and open new avenues for exploring solutions to unresolved problems in cosmology, such as the Hubble tension$ H_0 $ and$ \sigma_8 $ , within the framework of modified gravity theories. -
R. E. O. would like to thank Savvas Nesseris for his insightful discussions and valuable suggestions regarding genetic algorithms and also Xin Ren and Emmanuel N. Saridakis for their helpful discussions concerning f(T) gravity.
Model-independent reconstruction of f (T ) gravity using genetic algorithms
- Received Date: 2025-03-03
- Available Online: 2025-11-15
Abstract: In this paper, we use genetic algorithms, a specific machine learning technique, to achieve a model-independent reconstruction of



 DownLoad:
DownLoad: